By CDH Guest Author on December 19, 2016
Recently published work in the Journal of Medical Internet Research is the product of several years of collaboration between Professor Vwani Roychowdhury’s group in UCLA’s Department of Electrical Engineering, Professor Roshan Bastani’s group in the UCLA School of Public Health – Health Policy & Management, and myself, funded by a grant from the National Institutes of Health. As a folklorist who studies rumor and legend (stories that are told as true), I have been fascinated with the fact that the internet is, in many respects, the world’s largest dynamically self-archiving folklore archive. On the Internet, and particularly on the blogosphere and social media, there is an ongoing negotiation of cultural ideologies, with storytelling playing an important role. Stories, as we know from folklore, are remarkably efficient at conveying cultural ideology (norms, beliefs, values). However, it is often very hard to “discover” stories, largely because people in a community—and certainly on the internet–rarely tell a complete story. Rather they comment on or relate story parts.
Now, a great deal of work in social media has been focused on what people are talking about. What sets our work apart is that we focus not only on identifying what people are talking about online, but also how they are talking about it. By bringing in a structural narrative model, based on my work on 19th century Danish folklore collections believe it or not (the very first “big data” collections in Humanities and Anthropology were these folklore collections!) we are able to capture, in the aggregate, the emerging underlying narrative framework that gets activated as stories, story parts, or story comments as exchanged on these forums.
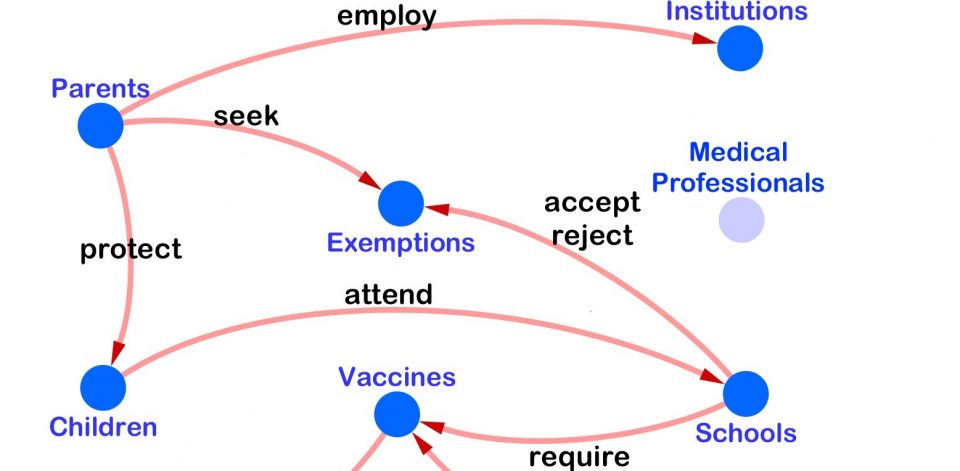
I think one of the main advances we’ve made is to recognize that the relationships between actants — the people and things that stories are “about”—are highly context dependent. This approach has allowed us to detect the emergence of the “exemption seeking” behavior we write about here that may have contributed to the measles epidemic several years ago, and if we pivot to political discussions, may help us in understanding the structure of “fake news.” In the future, it may help us craft stories that are community dependent, to address public health needs or other types of crises. And it may help us understand how and why certain stories gain traction in one community and not in another.
Timothy R. Tangherlini teaches folklore, literature and cultural studies at the University of California, Los Angeles, where he is a professor in the Scandinavian Section, and the Department of Asian Languages and Cultures. He is also an affiliate of the Center for Medieval and Renaissance Studies, the Religious Studies Program, and a faculty member in the Center for Korean Studies and the Center for European and Eurasian Studies.
The article on which he was a co-author was published on November 22, 2016 in the Journal of Medical Internet Research, Vol 2, No 2 (2016): Jul-Dec. It was also recently featured in the UCLA Newsroom: http://newsroom.ucla.edu/releases/ucla-researchers-teach-computer-to-read-the-internet.